The Science of Separating Voices: Advances in Target Speaker Extraction for Real World Applications
August 12, 2025
In the remote-first world of 2025, clarity in communication isn’t just desirable—it’s essential. Traditional noise cancellation methods tackle ambient sounds like keyboard clicks and traffic, but they fall short when multiple voices overlap. Enter Target Speaker Extraction (TSE): an innovative leap in AI audio solutions, designed to isolate and illuminate the voice that matters the most.
What Is Target Speaker Extraction?
Target Speaker Extraction is an advanced speech enhancement technology that selectively separates the voice of a designated speaker from a complex audio mixture, including other voices and surrounding noise. Unlike conventional noise cancellation techniques—which reduce all background sounds—TSE intelligently amplifies the selected speaker’s voice, even in bustling, overlapping-talker scenarios.
Equation 1: TSE Objective Function
\[
\hat{s} = \arg\max_{s} P(s \mid x, e)
\]
Where:
\(x\): Mixture audio signal
\(e\): Embedding vector of the target speaker
\(\hat{s}\): Estimated target speaker speech
TSE vs Traditional Noise Suppression
Feature comparison: Traditional Noise Cancellation vs Target Speaker Extraction
Feature
Traditional Noise Cancellation
Target Speaker Extraction
Handles overlapping speech
No
Yes
Requires speaker reference
No
Yes
Audio–visual capability
No
Yes
Ideal for transcription
Sometimes
Always
Scalable across distances
Limited
Robust even in far-field settings
While traditional noise suppression uniformly muffles ambient sounds, TSE goes further—leveraging audio-visual cues (like lip movement) or even EEG signals to pinpoint and amplify the correct voice. This makes it a foundational technology for target voice applications in large-scale virtual meetings and call centers.
Techniques behind TSE
Audio-Only Extraction with Reference Speech: Uses a brief sample of the speaker’s voice to generate a unique embedding. This enables the system to isolate them from noise and other talkers.
Audio–Visual Extraction via Lip Reading: Combines video of the speaker’s face—particularly lip movement—with audio inputs to strengthen extraction accuracy.
Body Gesture-Aided Extraction: Incorporates gestural data for environments with partial visual information.
Angle-Based Extraction Smart Glasses: Detects the user’s head orientation and gaze direction through wearable sensors to isolate the voice of the person they are looking at, ideal for AR/VR technology.
At the heart of TSE are two key subsystems:
Embedding System: Captures a speaker’s unique signature from audio, video, or neuro-data.
Extractor System: Uses that signature to separate the target voice from a noisy, multi-speaker mix.
Fig A. Audio only Target Speaker Extraction System (Enrollment and Mixture both are audios)
Fig B. Audio-VisualTarget Speaker Extraction System (Enrollment Video and Mixture is audio)
Audio-Visual TSE Using Lip Reading
In lip-based Audio-Visual Target Speaker Extraction (AV-TSE), synchronized video of the speaker’s face is processed using deep learning models. These models extract lip motion embeddings, which are fused with the audio stream in the extractor network.
AV-DPRNN Architecture
Audio-Only TSE Using Reference Speech
Audio-Only TSE systems operate without visual input. They rely on a single reference speech sample to identify the target speaker.
Equation 2: Mixture Model Representation
x = s + Σi=1N oi + b
Where:
s: Target speaker
oi: Interfering speakers
b: Background noise
Why TSE Is a Game-Changer for Call Centers and Conferences
Unmatched Voice Clarity: Ensures that the agent, presenter, or customer stands out—even amid chaos.
Heightened Accessibility: Aids listeners with hearing difficulties by suppressing redundant or overlapping speech.
Pristine Transcriptions: Dramatically improves automated note-taking, which is vital for compliance and analytics in call centers.
Reduced Cognitive Load: Less listening fatigue for participants in long meetings or high-volume support environments.
Far-Field Friendliness: Effective whether the speaker is near or distant—ideal when agents or participants are using varied microphones.
Noise-Robust Enrollment: Users can enroll their voice profile even in mildly noisy conditions—no need for a studio.
Multispeaker & Multilingual Support: Optimized for diverse, dynamic environments—seamlessly scaling to global teams.
Top TSE Solutions in the Market
When it comes to Target Speaker Extraction (TSE) and advanced AI audio solutions, a few players have made notable strides. However, Meeami Technologies stands at the forefront, delivering performance that’s not just competitive—but industry-leading.
TargetVoice by Meeami Technologies – Purpose-built for real-world complexity, TargetVoice goes beyond generic voice isolation by offering unmatched accuracy in multi-speaker, far-field, and multilingual scenarios. Optimized for call centers, conferences, and semiconductor-based edge deployments, TargetVoice combines robust noise suppression with precision speaker extraction to ensure the right voice is always heard—without distortion.
Microsoft Teams Voice Isolation – A built-in feature within Teams that uses AI to separate the active speaker’s voice from surrounding background sounds, helping improve clarity in virtual meetings.
Meeami’s TargetVoice isn’t just another TSE solution—it’s designed to scale across industries, from BPOs to automotive, healthcare, and broadcasting, with fine-tuned models that adapt to diverse environments and device constraints.
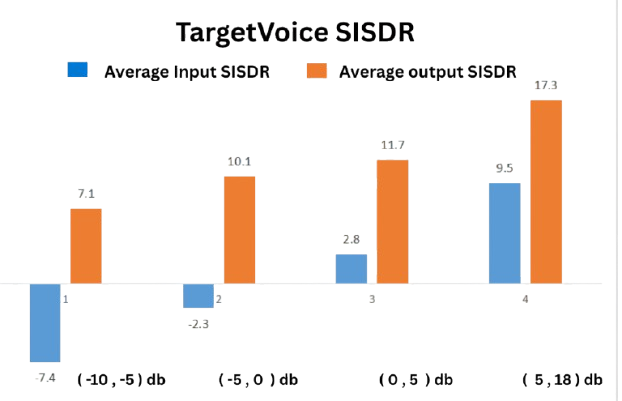
Insights Behind the Science
TSE performance is evaluated using respected metrics:
These metrics confirm both the signal fidelity and perceptual improvements, making target speaker extraction not just theoretically sound, but objectively measurable.
How Meeami Technologies Leads the Way
Our solution is designed with real-world complexity in mind. Here’s what sets us apart.
Optimized for Far-field Scenarios: Whether the speaker is nearby or across the room, our system performs reliably—without being affected by the distance from the microphone.
Robust to Both Speech and Background Noise: Unlike many systems that falter in noisy environments, our technology maintains high accuracy without distorting or interrupting the target speaker’s voice.
Enrollment Tolerant to Mild Noise: Users can enroll their voice profiles even in slightly noisy environments—eliminating the need for perfect silence during setup.
Built for Multi-speaker and Multilingual Use: Our models are fine-tuned to support multiple speakers and languages, making the solution ideal for diverse and dynamic environments.
Looking Ahead: The Future of Online Communication
Target Speaker Extraction isn’t just another feature—it’s a paradigm shift. As remote collaboration becomes more immersive and global, TSE will redefine standards for target voice clarity and reliability. Soon, you’ll find it embedded as a core function in every major communication suite—especially in sectors where clarity means business: support hotlines, critical stakeholder briefings, corporate town halls, and beyond.
Target Speaker Extraction SISDR Plot
Final Thoughts
In the era of hybrid work and digital-first interaction, you deserve every word to count. At Meeami Technologies, our Target Speaker Extraction solution brings unparalleled clarity, accessibility, and performance. Whether you’re managing a busy support center, leading a virtual summit, or striving for seamless international communication, the future is clear—and your voice has never sounded more vital.
See Meeami in Action
Experience AI-powered voice like never before. Watch our demos to hear the difference.
.png)
.png)
.png)
.png)
.png)